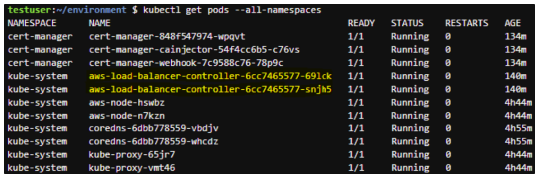
#1 Cluster Autoscaler 란?
Kubernetes에서 애플리케이션 수요에 맞추려면 워크로드를 실행하는 노드 수를 조정해야 할 수 있습니다. Kubernetes 사용의 가장 큰 장점 중 하나는 사용자 요구에 따라 인프라를 동적으로 확장할 수 있습니다.
(Cluster AutoScaler는 일반적으로 Cluster내 Deployment로 설치됩니다)

Cluster AutoScaler는 리소스 제약 조건으로 인해 예약할 수 없는 즉 Pending 상태의 Pod를 확인할 수 있습니다.

Cluster Autoscaler Process
문제가 발견되면 Pod 수요에 맞게 Worker Node 풀의 노드 수가 증가합니다. 또한 실행 중인 Pod가 부족한지 노드를 주기적으로 확인하고 필요에 따라 노드 수가 감소하여 WorkerNode 수를 자동으로 조정하여 노드 수를 ScaleOut 하거나 ScaleIn을 통해 효율적으로 비용 효과적인 인프라를 구성할 수 있습니다.

여러 종류의 ASG & Auto Scaling Policy
목적에 따라 다양한 ASG를 설정하고 다른 ASG Policy를 적용할 수 있습니다.
기존 Spot Instance는 On-demand 대비 80% 이상 할인률이 적용되었지만 중간에 허가 없이 종료 되지만, EKS의 Spot Interrupt Handler(DaemonSet)에 의해 정상적으로 실행 중인 Pod를 재배치 할 수 있습니다.
# Node 리소스 부족으로 Pod를 예약할 수 없는 경우
Cluster Autoscaler는 클러스터가 확장되어야 한다고 결정합니다. 확장기 인터페이스를 사용하면 다양한 포드 배치 전략을 적용할 수 있습니다. 현재 다음 전략이 지원됩니다.
- Random – 사용 가능한 노드 그룹을 무작위로 선택합니다.
- Most Pods – 가장 많은 노드를 예약할 수 있는 그룹을 선택합니다. 이것은 노드 그룹 간에 부하를 분산하는 데 사용할 수 있습니다.
- Least-waste – cpu, memory가 가장 적게 남는 node group을 선택
- price – cost가 가장 적은 node group을 선택
- priority - 우선순위가 높은 node group을 선택
#CA는 다음 옵션에서 노드를 제거불가
- 제한적인 PDB가 있는 포드.
- 배포된(즉, 기본적으로 노드에서 실행되지 않거나 PDB가 없는) kube-system 네임스페이스에서 실행되는 파드.
- 컨트롤러 객체가 지원하지 않는 포드(배포, 복제본 세트, 작업, 상태 저장 세트 등에 의해 생성되지 않음).
- 로컬 스토리지와 함께 실행되는 포드.
- 다양한 제약(리소스 부족, 일치하지 않는 노드 선택기 또는 선호도, 일치하는 반선호도 등)으로 인해 다른 곳으로 이동할 수 없는 실행 중인 포드.
#2 Cluster Autoscaler 설치
전제 조건
Cluster Autoscaler를 배포하려면 먼저 다음 사전 조건을 충족해야 합니다.
- 기존 Amazon EKS 클러스터
- 클러스터에 대한 기존 IAM OIDC 공급자입니다. 하나가 있는지 또는 생성해야 하는지 여부를 확인하려면 클러스터에 대한 IAM OIDC 공급자 생성 섹션을 참조하세요.
- Auto Scaling 그룹 태그가 있는 노드 그룹 Cluster Autoscaler에서는 Auto Scaling 그룹에 다음과 같은 태그가 있어야 자동 검색됩니다.
eksctl을 사용하여 노드 그룹을 생성한 경우 이 태그는 자동으로 적용됩니다.eksctl을 사용하지 않았다면 다음 태그로 Auto Scaling 그룹에 수동으로 태그를 지정해야 합니다. 자세한 내용은 Linux 인스턴스용 Amazon EC2 사용 설명서에서 Amazon EC2 리소스 태깅을 참조하세요.- k8s.io/cluster-autoscaler/<cluster-name> : owned
k8s.io/cluster-autoscaler/enabled : TRUE
IAM 정책 및 역할 생성
- IAM 정책을 생성합니다.
- 다음 콘텐츠를
cluster-autoscaler-policy.json이라는 파일에 저장합니다. 기존 노드 그룹이eksctl을 사용하여 생성되었고-asg-access옵션을 사용했다면 이 정책이 이미 존재하며 2단계로 건너뛸 수 있습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeLaunchTemplateVersions"
],
"Resource": "*",
"Effect": "Allow"
}
]
}다음 명령을 사용하여 정책을 생성합니다. policy-name의 값을 변경할 수 있습니다.
aws iam create-policy \
--policy-name AmazonEKSClusterAutoscalerPolicy \
--policy-document file://cluster-autoscaler-policy.json- iamserviceaccount 생성
eksctl을 사용하여 Amazon EKS 클러스터를 생성한 경우 다음 명령을 실행합니다. -asg-access 옵션을 사용하여 노드 그룹을 생성한 경우 <AmazonEKSClusterAutoscalerPolicy>를 eksctl이 생성한 IAM 정책의 이름으로 바꿉니다. 정책 이름은 eksctl-<cluster-name>-nodegroup-ng-<xxxxxxxx>-PolicyAutoScaling과 유사합니다.
eksctl create iamserviceaccount \
--cluster=<my-cluster> \
--namespace=kube-system \
--name=cluster-autoscaler \
--attach-policy-arn=arn:aws:iam::<AWS_ACCOUNT_ID>:policy/<AmazonEKSClusterAutoscalerPolicy> \
--override-existing-serviceaccounts \
--approveasg-access옵션을 사용하여 노드 그룹을 생성한 경우eksctl이 생성하여 해당eksctl이 노드 그룹에 대해 생성한 Amazon EKS 노드 IAM 역할에 연결한 IAM 정책을 분리합니다. Cluster Autoscaler가 제대로 작동하도록 노드 IAM 역할에서 정책을 분리합니다. 정책을 분리해도 노드의 다른 포드에는 정책의 권한이 부여되지 않습니다.
- 생성 확인
다음 명령어로 iamserviceaccount 의 생성을 확인하고,
AWS Management Console IAM Role ARN 을 확인합니다. (Cluster Autoscaler에서 사용)
kubectl get sa -n kube-system | grep -i cluster-autoscaler
Cluster Autoscaler 배포
- Cluster Autoscaler YAML 파일을 다운로드합니다.
curl -o cluster-autoscaler-autodiscover.yaml https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml- YAML 파일을 수정하고 을 클러스터 이름으로 바꿉니다.

- YAML 파일을 클러스터에 적용합니다.
kubectl apply -f cluster-autoscaler-autodiscover.yaml- 이전에 생성한 IAM 역할의 ARN을 사용하여
cluster-autoscaler서비스 계정에 주석을 지정합니다.<example values>를 위에 생성한 역할의 ARN 값으로 바꿉니다.
kubectl annotate serviceaccount cluster-autoscaler \
-n kube-system \
eks.amazonaws.com/role-arn=arn:aws:iam::<ACCOUNT_ID>:role/<AmazonEKSClusterAutoscalerRole>ServiceAccount - cluster-autoscaler Annotation 변경을 확인합니다.
$ kubectl describe sa -n kube-system cluster-autoscaler
========================================================
Name: cluster-autoscaler
Namespace: kube-system
Labels: k8s-addon=cluster-autoscaler.addons.k8s.io
k8s-app=cluster-autoscaler
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::279424994673:role/eksctl-EKS-Project-addon-iamserviceaccount-k-Role1-13DTLSGQPNNJB
Image pull secrets: <none>
Mountable secrets: cluster-autoscaler-token-6x8mg
Tokens: cluster-autoscaler-token-6x8mg
Events: <none>- 다음 명령으로 배포를 패치하여
cluster-autoscaler.kubernetes.io/safe-to-evict주석을 Cluster Autoscaler 포드에 추가합니다. CA가 자체 포드가 실행 중인 노드를 제거하는 것을 방지하기 위해 false로 설정합니다. 해당 주석의 값이 True인 경우 ClusterAutoscaler가 노드를 제거할 수 없습니다.
kubectl patch deployment cluster-autoscaler \
-n kube-system \
-p '{"spec":{"template":{"metadata":{"annotations":{"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"}}}}}'
- 다음 명령을 사용하여 Cluster Autoscaler 배포를 편집합니다.
kubectl -n kube-system edit deployment.apps/cluster-autoscaler추가할 Flag
balance-similar-node-groupsskip-nodes-with-system-pods=false
spec:
containers:
- command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false
- --expander=least-waste
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/<YOUR CLUSTER NAME>
- --balance-similar-node-groups
- --skip-nodes-with-system-pods=false파일을 저장한 다음 종료하여 변경 사항을 적용합니다
- 웹 브라우저의 GitHub에서 Cluster Autoscaler [릴리스(releases)] 페이지를 열고 클러스터의 Kubernetes 메이저 및 마이너 버전과 일치하는 최신 Cluster Autoscaler 버전을 검색합니다. 예를 들어 클러스터의 Kubernetes 버전이 1.21이라면 1.21로 시작하는 최신 Cluster Autoscaler 릴리스를 검색합니다. 다음 단계에서 사용할 수 있도록 이 릴리스의 의미 체계 버전(
1.21.*n*)을 적어 둡니다.
(해당 부분 유의 Version에 따라 호환성)
- 다음 명령을 사용하여 Cluster Autoscaler 이미지 태그를 이전 단계에서 적어 둔 버전으로 설정합니다.
1.21.n을 사용자의 고유한 값으로 교체하고 확인합니다.
kubectl set image deployment cluster-autoscaler \
-n kube-system \
cluster-autoscaler=k8s.gcr.io/autoscaling/cluster-autoscaler:v1.21.2#3 동작 검증
테스트용 Nginx Deployment 생성
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 2
memory: 2Gi
EOF주목하여야 할 부분은 spec.spec.containers.resource 부분이다.
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 2
memory: 2Gi
리소스의 요청이 노드의 자원을 초과하므로 ClusterAutocaler는 AWS ASG를 통해 노드를 추가합니다.

노드가 추가된 후 Pod의 Pending 상태가 Running으로 변경됩니다.

# 4 참고문서
Cluster Autoscaler 배포를 최적화하기 위한 고려 사항
Cluster Autoscaler 공식 가이드
Cluster Autoscaler 에 대한 이해
'IT > Kubernetes' 카테고리의 다른 글
| kubeconfig를 통해 다른서버 접근 (2) | 2023.11.09 |
|---|---|
| Kubesprary를 통한 Upgrade와 Node 추가 (0) | 2023.11.09 |
| AWS LoadBalancer Controller 개념과 설치 구성 방법 (0) | 2023.07.26 |
| 카오스 엔지니어링의 개념, Tool, 이점 (0) | 2023.07.21 |
| 7가지 간단한 Kubernetes 성능 최적화 팁 (0) | 2023.07.11 |