Kubernetes에서 애플리케이션 수요에 맞추려면 워크로드를 실행하는 노드 수를 조정해야 할 수 있습니다. Kubernetes 사용의 가장 큰 장점 중 하나는 사용자 요구에 따라 인프라를 동적으로 확장할 수 있습니다.
(Cluster AutoScaler는 일반적으로 Cluster내 Deployment로 설치됩니다)
Cluster AutoScaler는 리소스 제약 조건으로 인해 예약할 수 없는 즉 Pending 상태의 Pod를 확인할 수 있습니다.
Cluster Autoscaler Process
문제가 발견되면 Pod 수요에 맞게 Worker Node 풀의 노드 수가 증가합니다. 또한 실행 중인 Pod가 부족한지 노드를 주기적으로 확인하고 필요에 따라 노드 수가 감소하여 WorkerNode 수를 자동으로 조정하여 노드 수를 ScaleOut 하거나 ScaleIn을 통해 효율적으로 비용 효과적인 인프라를 구성할 수 있습니다.
여러 종류의 ASG & Auto Scaling Policy
목적에 따라 다양한 ASG를 설정하고 다른 ASG Policy를 적용할 수 있습니다.
기존 Spot Instance는 On-demand 대비 80% 이상 할인률이 적용되었지만 중간에 허가 없이 종료 되지만, EKS의 Spot Interrupt Handler(DaemonSet)에 의해 정상적으로 실행 중인 Pod를 재배치 할 수 있습니다.
# Node 리소스 부족으로 Pod를 예약할 수 없는 경우
Cluster Autoscaler는 클러스터가 확장되어야 한다고 결정합니다. 확장기 인터페이스를 사용하면 다양한 포드 배치 전략을 적용할 수 있습니다. 현재 다음 전략이 지원됩니다.
Random – 사용 가능한 노드 그룹을 무작위로 선택합니다.
Most Pods – 가장 많은 노드를 예약할 수 있는 그룹을 선택합니다. 이것은 노드 그룹 간에 부하를 분산하는 데 사용할 수 있습니다.
Least-waste – cpu, memory가 가장 적게 남는 node group을 선택
price – cost가 가장 적은 node group을 선택
priority - 우선순위가 높은 node group을 선택
#CA는 다음 옵션에서 노드를 제거불가
제한적인 PDB가 있는 포드.
배포된(즉, 기본적으로 노드에서 실행되지 않거나 PDB가 없는) kube-system 네임스페이스에서 실행되는 파드.
컨트롤러 객체가 지원하지 않는 포드(배포, 복제본 세트, 작업, 상태 저장 세트 등에 의해 생성되지 않음).
로컬 스토리지와 함께 실행되는 포드.
다양한 제약(리소스 부족, 일치하지 않는 노드 선택기 또는 선호도, 일치하는 반선호도 등)으로 인해 다른 곳으로 이동할 수 없는 실행 중인 포드.
다음 명령을 사용하여 정책을 생성합니다. policy-name의 값을 변경할 수 있습니다.
aws iam create-policy \
--policy-name AmazonEKSClusterAutoscalerPolicy \
--policy-document file://cluster-autoscaler-policy.json
iamserviceaccount 생성
eksctl을 사용하여 Amazon EKS 클러스터를 생성한 경우 다음 명령을 실행합니다. -asg-access 옵션을 사용하여 노드 그룹을 생성한 경우 <AmazonEKSClusterAutoscalerPolicy>를 eksctl이 생성한 IAM 정책의 이름으로 바꿉니다. 정책 이름은 eksctl-<cluster-name>-nodegroup-ng-<xxxxxxxx>-PolicyAutoScaling과 유사합니다.
asg-access 옵션을 사용하여 노드 그룹을 생성한 경우 eksctl이 생성하여 해당 eksctl이 노드 그룹에 대해 생성한 Amazon EKS 노드 IAM 역할에 연결한 IAM 정책을 분리합니다. Cluster Autoscaler가 제대로 작동하도록 노드 IAM 역할에서 정책을 분리합니다. 정책을 분리해도 노드의 다른 포드에는 정책의 권한이 부여되지 않습니다.
생성 확인
다음 명령어로 iamserviceaccount 의 생성을 확인하고, AWS Management Console IAM Role ARN 을 확인합니다. (Cluster Autoscaler에서 사용)
kubectl get sa -n kube-system | grep -i cluster-autoscaler
다음 명령으로 배포를 패치하여 cluster-autoscaler.kubernetes.io/safe-to-evict 주석을 Cluster Autoscaler 포드에 추가합니다. CA가 자체 포드가 실행 중인 노드를 제거하는 것을 방지하기 위해 false로 설정합니다. 해당 주석의 값이 True인 경우 ClusterAutoscaler가 노드를 제거할 수 없습니다.
웹 브라우저의 GitHub에서 Cluster Autoscaler [릴리스(releases)] 페이지를 열고 클러스터의 Kubernetes 메이저 및 마이너 버전과 일치하는 최신 Cluster Autoscaler 버전을 검색합니다. 예를 들어 클러스터의 Kubernetes 버전이 1.21이라면 1.21로 시작하는 최신 Cluster Autoscaler 릴리스를 검색합니다. 다음 단계에서 사용할 수 있도록 이 릴리스의 의미 체계 버전(1.21.*n*)을 적어 둡니다.
(해당 부분 유의 Version에 따라 호환성)
다음 명령을 사용하여 Cluster Autoscaler 이미지 태그를 이전 단계에서 적어 둔 버전으로 설정합니다. 1.21.n을 사용자의 고유한 값으로 교체하고 확인합니다.
kubectl set image deployment cluster-autoscaler \
-n kube-system \
cluster-autoscaler=k8s.gcr.io/autoscaling/cluster-autoscaler:v1.21.2
AWS LoadBalancer Controller는 Kubernetes 클러스터의 Elastic Load Balancer(NLB or ALB)를 관리하는 데 Ingress.yaml 템플릿에 명시 된 Rule을 통해 LoadBalancer를 관리하는 컨트롤러 입니다. (Application Load Balancer & Network Load Balancer를 모두 지원합니다)
Kubernetes Application은 외부 트래픽에 노출 되어야 하며, EKS Client는 ELB를 사용하여 태스크를 수행합니다.
Controller를 통해 External Access Allow
Controller를 통해 만들면 Ingress Annotation 값 확인하여, Controller가 LoadBalancer를 대신 만들어 주는 형태입니다.
이때 사용되는 인그레스(Ingress) 는 L7 영역의 요청을 처리합니다.
주로 클러스터 외부에서 쿠버네티스 내부로 접근할 때, 요청들을 어떻게 처리할지 정의해놓은 규칙이자 리소스 오브젝트입니다. 한마디로 외부의 요청이 내부로 접근하기 위한 관문의 역할을 하는 것이죠.
Ingress를 AWS Loadbalancer Controller를 통해 ALB로 선언
외부 요청에 대한 로드 밸런싱, TLS/SSL 인증서 처리, HTTP 경로에 대한 라우팅 등을 설정할 수 있습니다.
NLB는 LoadBalancer 유형의 Kubernetes 서비스에 대한 응답으로 생성되며, 초당 수백만 건의 요청으로 확장할 수 있는 고성능 트래픽 서비스를 제공합니다.
EC2 Loadbalancer 항목에서 추가 됨
AWS Loadbalancer Controller는 Kubernetes Ingress 객체에 대한 반응으로 Application Load Balancer를 자동으로 프로비저닝 합니다.
AWS Load Balancer Controller에서 지원하는 Traffic Mode는 Default Instance를 대상으로 Cluster 내 node를 ALB 대상으로 등록하는 방법은 ALB에 도달하는 트래픽은 NodePort로 Routing 된 다음 Pod로 프록시 하거나 IP기반으로 Pod를 IP대상으로 등록하는 방법이 있습니다.
ALB에 도달하는 트래픽은 Pod로 직접 Routing되며, 해당 트래픽 모드를 사용하기 위해 ‘ingress.yaml’파일에 Annotation을 사용하여 지정해야 합니다.
728x90
ALB가 생성되면서 각 Application 별 PATH 기반 트래픽 분기
쿠버네티스에서 서비스 타입 중, NodePort 혹은 LoadBalancer로도 외부로 노출할 수 있지만 인그레스 없이 서비스를 사용할 경우, 모든 서비스에게 라우팅 규칙 및 TLS/SSL 등의 상세한 옵션들을 적용해야합니다. 그래서 인그레스가 필요합니다.
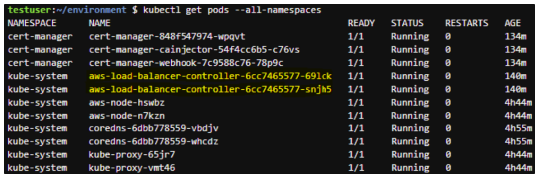
Pod형태로 LoadBalancer Controller의 Running 상태
#2. 설치방법
1. Service Account 에 대한 IAM 역할 설정
AWS Load Balancer 컨트롤러를 배포하기 전, 클러스터에 대한 IAM OIDC(OpenID Connect identity Provider)를 생성합니다. 쿠버네티스가 직접 관리하는 사용자 계정을 의미하는 service account에 IAM role을 연결하기 위해, 클러스터에 IAM OIDC provider가 존재해야 합니다.
Kubernetes는 복잡한 도구입니다.대부분의 복잡한 도구의 경우와 마찬가지로 Kubernetes에서 최적의 성능을 얻는 것은 까다로울 수 있습니다.대부분의 Kubernetes 배포는 성능을 최대화하기 위해 미세 조정되지 않습니다(그렇더라도 사용자 환경에 최적인 방식으로 조정되지 않을 가능성이 높습니다).
이러한 현실을 염두에 두고 Kubernetes 성능 최적화에 대한 팁을 계속 읽으십시오.이제 막 클러스터 구축을 시작했거나 이미 프로덕션 환경을 실행하고 있는지 여부에 관계없이 Kubernetes 성능을 개선하기 위해 수행할 수 있는 간단한 작업에 중점을 둘 것입니다.
1새 작업자 노드를 생성하기 전에 기존 작업자 노드에 리소스 추가
아마도 Kubernetes 성능을 개선하는 가장 확실한 방법은 클러스터에 더 많은 작업자 노드를 추가하는 것입니다.작업자가 많을수록 더 많은 리소스를 사용하여 워크로드를 강화할 수 있습니다.또한 노드가 많을수록 많은 노드가 실패하여 워크로드가 실패할 가능성이 줄어들기 때문에 가용성이 향상됩니다.
그러나 작업자 노드를 최대한 활용하려는 경우 새 노드를 생성하는 대신 기존 작업자 노드에 메모리 및 CPU 리소스를 추가하여 더 많은 비용을 절감할 수 있습니다.즉, 각각 8GB의 메모리가 있는 40개의 노드보다 각각 16GB의 메모리가 있는 20개의 노드를 갖는 것이 좋습니다.
이것은 두 가지 이유로 사실입니다.첫째, 호스트 운영 체제로 인해 각 노드에 일정량의 오버헤드가 있습니다.노드 수가 적다는 것은 그런 식으로 낭비되는 리소스가 적다는 것을 의미합니다.둘째, 노드가 많을수록 스케줄러, kube-proxy 및 기타 구성 요소가 모든 것을 추적하기 위해 작동해야 합니다.
당연히 가용성을 고려해야 하며 가용성 목표를 충족하기 위한 최소한의 작업자 노드가 있는지 확인해야 합니다.그러나 이 임계값을 넘으면 전체 노드 수를 최대화하려고 하기보다 각 노드에 할당된 리소스를 가능한 한 많이 할당하여 전반적인 성능 효율성을 높일 수 있습니다.극단적으로 가지 마십시오(예를 들어 단일 노드에서 24테라바이트의 메모리를 원하지 않을 것입니다). 노드가 실패할 경우 해당 리소스를 잃을 위험이 있기 때문입니다.
물론 노드의 리소스 할당을 결정하는 데 많은 유연성이 있을 수도 있고 없을 수도 있습니다.클라우드에서 실행되는 가상 머신인 경우 원하는 만큼 리소스를 할당할 수 있습니다.온프레미스 가상 머신이나 물리적 서버라면 더 까다롭습니다.
728x90
2여러 마스터 노드 사용
Kubernetes 클러스터에서 여러 마스터를 사용하는 주된 이유는 고가용성을 달성하기 위해서입니다.마스터가 많을수록 마스터가 모두 실패하여 클러스터가 중단될 가능성이 줄어듭니다.
그러나 더 많은 마스터를 추가하면 마스터에서 호스팅되는 필수 Kubernetes 구성 요소(예: 스케줄러, API 서버 및 기타)에 더 많은 호스팅 리소스를 제공하므로 성능 이점도 제공됩니다.Kubernetes는 모든 마스터 노드의 집합적 리소스를 사용하여 이러한 구성 요소를 구동합니다.
따라서 마스터(또는 2개 또는 4개)를 추가하는 것은 Kubernetes 클러스터의 성능을 향상시키는 쉽고 좋은 방법입니다.
3작업자 노드 점수 제한 설정
Kubernetes 스케줄러가 수행하는 작업의 일부는 작업자 노드를 "점수"하는 것입니다. 즉, 워크로드를 처리하는 데 적합한 작업자 노드를 결정합니다.수십 개 이상의 작업자 노드가 있는 클러스터에서 스케줄러는 결국 모든 작업자 노드를 확인하는 데 시간을 낭비할 수 있습니다.
이러한 비효율성을 방지하기 위해 percentOfNodesToScore 매개변수를 100보다 낮은 백분율로 설정할 수 있습니다. 그러면 스케줄러는 지정한 노드의 백분율만 확인합니다.
4리소스 할당량 설정
특히 여러 팀이 공유하는 대규모 클러스터에서 Kubernetes 성능을 향상시키는 간단하지만 매우 효과적인 방법은 리소스 할당량을 설정하는 것입니다.리소스 할당량은 지정된 네임스페이스에서 사용할 수 있는 CPU, 메모리 및 스토리지 리소스의 양에 대한 제한을 설정합니다.
따라서 클러스터를 네임스페이스로 나누고 각 팀에 다른 네임스페이스를 제공하고 각 네임스페이스에 대한 리소스 할당량을 설정하면 모든 워크로드가 리소스를 공평하게 공유하도록 하는 데 도움이 됩니다.
리소스 할당량은 그 자체로 성능 최적화가 아닙니다.그들은 시끄러운 이웃 문제에 대한 해결책에 가깝습니다.그러나 각 네임스페이스가 작업을 적절하게 수행하는 데 필요한 리소스를 가지고 있는지 확인하는 데 도움이 됩니다.
5제한 범위 설정
워크로드에서 사용하는 리소스를 제한하고 싶지만 해당 워크로드가 다른 워크로드와 동일한 네임스페이스에서 실행되는 경우에는 어떻게 해야 합니까?이것이 한계 범위가 하는 일입니다.
리소스 할당량은 각 네임스페이스가 소비할 수 있는 리소스 수에 대한 제한을 설정하는 반면 제한 범위는 포드당 또는 컨테이너당 기준으로 동일한 작업을 수행합니다.
단순화를 위해 대부분의 경우 모범 사례는 네임스페이스 및 리소스 할당량을 사용하여 워크로드를 분할하는 것입니다.그러나 이러한 접근 방식이 실용적이지 않은 경우 제한 범위를 사용하면 개별 포드 또는 컨테이너가 원하는 대로 수행하는 데 필요한 리소스를 갖도록 보장할 수 있습니다.
6엔드포인트 슬라이스 설정
엔드포인트 슬라이스는 서비스 및 포트 조합을 기반으로 네트워크 엔드포인트를 함께 그룹화할 수 있는 거의 논의되지 않은 Kubernetes 기능입니다.설정되면 kube-proxy는 트래픽 라우팅 방법을 결정할 때 이를 참조합니다.
엔드포인트가 많은 환경에서 엔드포인트 슬라이스는 클러스터 내에서 트래픽을 라우팅하기 위해 kube-proxy가 수행해야 하는 작업량을 줄임으로써 성능을 향상시킬 수 있습니다.
7미니멀리스트 호스트 OS 사용
마지막으로 기본적이지만 효과적인 팁입니다. Kubernetes 클러스터를 호스팅하는 운영 체제가 가능한 한 최소인지 확인하십시오.Kubernetes를 실행하는 데 반드시 필요하지 않은 추가 구성 요소는 리소스 낭비로 이어져 클러스터의 성능을 저하시킵니다.
사용하는 Kubernetes 배포에 따라 호스트 OS를 선택할 수도 있고 그렇지 않을 수도 있습니다.하지만 그렇다면 설치 공간이 최소인 Linux 배포판을 선택하십시오.
결론
Kubernetes는 많은 작업을 자동으로 수행하도록 설계되었습니다.그러나 자체 성능 관리를 자동화하지는 않습니다.Kubernetes 전용 인프라에서 최고의 성능을 얻으려면 인프라를 설계하는 방법과 특정 Kubernetes 구성 요소를 구성하는 방법에 대해 현명해야 합니다.